Integrate many data sources into your data warehouse with DBT
We walk through our DBT project structure and how it helps us transform data from many point-of-sale (POS) systems into a retail analytics data warehouse.
Background
For the last several years, we have been building and maintaining a retail sales data warehouse for Cookies. Because Cookies products are sold in stores from a large number of partners, there are many different point-of-sale (POS) systems that we need to fetch data from and integrate into a unified analytics schema. This integration as well as all other transformations are performed by DBT.
File Structure
Here is the general structure of our models directory in our DBT project without showing the sql files inside.
/path/to/cookies-dbt/
models
├── etc
├── schema.yml
├── retail
│ ├── core
│ └── staging
│ ├── blaze
│ │ ├── base
│ │ └── staged
│ ├── cova
│ │ ├── base
│ │ └── staged
│ ├── flowhub
│ │ ├── base
│ │ └── staged
│ ├── iheartjane
│ │ ├── base
│ │ └── staged
│ └── meadow
│ ├── base
│ └── staged
└── wholesale
├── core
└── staging
├── distru
│ ├── base
│ └── staged
├── herbl
│ ├── base
│ └── stg
└── nabis
├── base
└── staged
You can see our separation of retail and wholesale data as well as core and staging subdirectories for each. Furthermore in the retail staging directory we have subdirectories for each POS source system - blaze, cova, flowhub, iheartjane, and meadow. Then in those we have a base and stg subdirectory.
Generally the path of data is to move from source-table -> base -> staged -> staging -> core. This is along the lines of DBT's project structure recommendations with some differences in naming and to allow for integration of multiple sources.
We will now follow the creation of one of our most used tables from one POS source system in particular - Blaze as shown in the DBT dag below. Line items are the grain of our warehouse and retail_lineitems is our most commonly used fact table.
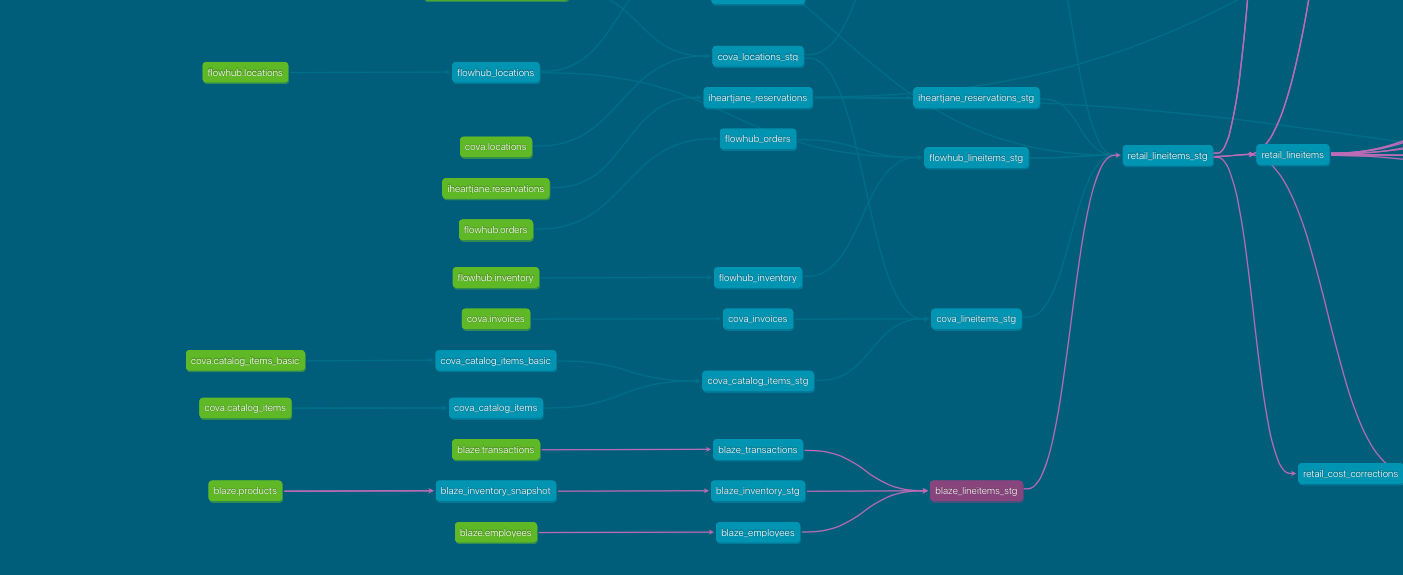
Base Tables
Here we show the structure of our project again but at a deeper level. This is the staging directory in our retail directory including blaze tables.
models/retail/staging
├── retail_cost_corrections.sql
├── retail_inventory_snapshot_stg.sql
├── retail_lineitems_stg.sql
├── retail_locations_map.sql
└── retail_segment_stg.sql
├── blaze
│ ├── base
│ │ ├── blaze_brands.sql
│ │ ├── blaze_categories.sql
│ │ ├── blaze_employees.sql
│ │ ├── blaze_products.sql
│ │ ├── blaze_store.sql
│ │ └── blaze_transactions.sql
│ └── staged
│ ├── blaze_customers_stg.sql
│ ├── blaze_inventory_stg.sql
│ ├── blaze_lineitems_stg.sql
│ └── blaze_locations_stg.sql
├── cova
│ ├── base
│ └── staged
├── flowhub
│ ├── base
│ └── staged
├── iheartjane
│ ├── base
│ └── staged
└── meadow
├── base
└── staged
Though we don't show the files for the other POS systems, the process for them is the same. Our base tables are the landing space for our ELT ingest processes. In some cases these are fetched via an API and in others they are scraped from a website. These tables are hopefully an exact replica of the ones in the source systems.
Because each POS system has a different set of endpoints and structure within each endpoint, the transformations for that endpoint have to performed differently. Here we include a sample of our blaze_lineitems_stg.sql file. Don't worry about following the specifics of the logic, this is just to give you an idea of what kinds of transformations may happen at this stage.
...
, orders as (SELECT * FROM {{ref('blaze_transactions')}})
, lines as (
SELECT
orders.order_id
, x.*
, CASE WHEN x.quantity=0 THEN NULL --x."finalPrice"
ELSE (x."finalPrice")*((x.quantity-COALESCE(x."totalRefundQty",0))/x.quantity)
END AS line_finalprice_after_refunds
, CASE WHEN x.quantity=0 THEN x."calcPreTax"
ELSE x."calcPreTax"*((x.quantity-COALESCE(x."totalRefundQty",0))/x.quantity)
END AS line_included_tax_after_refunds
, CASE WHEN x.quantity=0 THEN x."calcTax"
ELSE x."calcTax"*((x.quantity-COALESCE(x."totalRefundQty",0))/x.quantity)
END AS line_additional_tax_after_refunds
, CASE WHEN x.quantity=0 THEN x."calcDiscount"
ELSE x."calcDiscount"*((x.quantity-COALESCE(x."totalRefundQty",0))/x.quantity)
END AS line_discount_after_refunds
, CASE WHEN x.quantity=0 THEN NULL
ELSE (x.quantity-COALESCE(x."totalRefundQty",0))/x.quantity
END AS qty_remain_pct
FROM orders
, jsonb_to_recordset(cart_items) as x(
id varchar(50)
, "batchId" varchar(100)
, "calcDiscount" decimal(16,3)
, "calcPreTax" decimal(16,3)
, "calcTax" decimal(16,3)
, cogs decimal(16,2)
, cost decimal(16,2)
-- , discount decimal(16,2) -- This could be a $ amount or %, instead use calc:
, "finalPrice" decimal(16,3)
, "orderItemId" varchar(50)
, "productId" varchar(50)
, quantity decimal(16,2)
, "taxOrder" varchar(50)
, "totalRefundQty" decimal(16,2)
, "unitPrice" decimal(16,2)
)
)
, order_line_totals AS ( --order total less returns
SELECT
x.order_id
, SUM(x."finalPrice") AS sum_line_finalprice
, SUM(line_finalprice_after_refunds) AS sum_line_finalprice_after_refunds
, SUM(x."calcPreTax") AS sum_included_tax
, SUM(line_included_tax_after_refunds) AS sum_line_included_tax_after_refunds
, SUM(x."calcTax") AS sum_additional_tax
, SUM(line_additional_tax_after_refunds) AS sum_line_additional_tax_after_refunds
, SUM(x."calcDiscount") AS sum_line_discount
, SUM(line_discount_after_refunds) AS sum_line_discount_after_refunds
FROM lines x
JOIN orders ON orders.order_id=x.order_id
GROUP BY 1
)
, order_discount AS (
SELECT
orders.order_id
, orders.discount - order_line_totals.sum_line_discount AS order_added_discount
FROM orders
JOIN order_line_totals ON orders.order_id = order_line_totals.order_id
)
...
Note for instance that we use the blaze transactions base table to create our lineitems. In that table the grain is an order, each of which contains a JSON array with all lineitems. This array must be extracted into multiple rows with the jsonb_to_recordset function. Then order_line_totals are computed so that discounts to the entire order can be included in the lineitems and aggregations across the entire table add up correctly. At this point we are done with all our blaze-specific transformations.
Staging Tables
Now we want to insert all of the rows in our newly built blaze_lineitems_stg into retail_lineitems_stg. To do this, we need to be sure that blaze_lineitems_stg has all of the necessary columns - the list of which are shown in retail_lineitems_stg.
...
{%- set union_tables = [
'flowhub_lineitems_stg',
'meadow_lineitems_stg',
'blaze_lineitems_stg',
'cova_lineitems_stg'
] -%}
{%- set union_cols = [
"brand",
"budtender",
"cashier",
"completed_at_local",
"completed_at",
"customer_id",
"customer_type",
"discount",
"extracted_at",
"lineitem_id",
"location_id_ext",
"order_id",
"order_type",
"product_category",
"product_name",
"quantity",
"sales",
"sku",
"source",
"strain_name",
"timezone",
"totalcash",
"totaltax",
"unit_cost",
"unit_discount",
"unit_of_weight",
"product_weight_grams",
"unit_price",
"unit_totalcash",
"upc"
] -%}
with unioned as (
{% for t in union_tables %}
SELECT
{% for col in union_cols %}
{{ col }}{% if not loop.last %}, {% endif %}
{% endfor %}
FROM {{ ref(t) }}
{% if is_incremental() %}
WHERE extracted_at >= (CURRENT_DATE - interval '{{ var('lookback') }}')
{% endif %}
{% if not loop.last %}UNION ALL {% endif %}
{% endfor %}
)
....
Though we perform a number of other transformation afterwards, this is the basic idea behind our staging tables - assume that these columns exist in the source staging table and then union all of them together with an additional source column so that you know the source of every row.
Core Tables
Finally we get to our core tables. These are the tables that make up our analytics schema that we expose to analysts and BI Tools. They must be as user-friendly as possible - traditionally these are Kimball-style fact and dimension tables. In our experience we have found it useful to work backwards - start with the most frequently asked questions by analysts and imagine a table that can answer them. Then our core table transformations are anything needed to create this table. In the case of retail_lineitems for instance, this can be seen as a fact table but it has many additional attributes - for instance the median sales price for this item or the most recent previous sale for this item. Both of these are attributes may be tricky or time-consuming for an analyst to compute.
Inventory
One form of data that does not follow the above pipeline is inventory. This is because we track inventory using DBT's snapshot feature. This allows us to look back in time at previous inventory levels even if the source system's api doesn't include those. All snapshot models are in a snapshots folder at the top level of the project
/path/to/cookies-dbt/
├── ...
├── models
│ ├── etc
│ ├── retail
│ ├── schema.yml
│ └── wholesale
├── packages.yml
├── snapshots
│ ├── blaze_inventory_snapshot.sql
│ ├── cova_inventory_snapshot.sql
│ ├── distru_inventory_snapshot.sql
│ ├── flowhub_inventory_snapshot.sql
│ ├── herbl_inventory_snapshot.sql
│ ├── meadow_inventory_snapshot.sql
│ └── nabis_inventory_snapshot.sql
├── ...
Let's look specifically at some of blaze_inventory_snapshot.sql. Note that we snapshot the source table rather than any downstream model as is recommended in the docs.
...
with max_date as (
select max(date_trunc('day',_sdc_batched_at)) as last_run_date -- need this and filtering below subquery to last_run_date in order to only have the most current inventory as defined by _sdc_batched_at timestamp.
from {{ source('blaze', 'products') }} -- inventory does not support deletions and we need to only snapshot current inventory in order to avoid phantom products
SELECT
_sdc_batched_at,
_sdc_deleted_at,
_sdc_extracted_at,
active,
instock,
...
quantities,
vendorid,
FROM {{ source('blaze', 'products') }}
join max_date on 1=1
where date_trunc('day',_sdc_batched_at)= max_date.last_run_date
The ETL tool that we use - Stitch - adds the _sdc prefixed columns to help you understand when records were added, changed, or removed from the table. We use _sdc_batched_at to filter down the blaze_products table to only those inserted on the most recent run date. The next snapshot will capture the next batch of inserted records and so on.
From here, going back to our staged tables, blaze_inventory_stg refers to blaze_inventory_snapshot rather than any blaze_inventory base table. You can think of the snapshot tables as a different form of base table. From this point things progress as usual - our retail_inventory_snapshot_stg model unions blaze_inventory_stg with all other inventory_stg models and then our core retail_inventory model is built on top of it.
Conclusion
Though this was a small piece of our DBT project, we hope that it's useful to read as an example of integrating many source systems into one data warehouse. We try and adhere to DBT's best practices as well as we can. This structure has been working well for us and for Cookies. If you would hear more about this project please don't hesitate to reach out.