Continuous API Data ELT into BigQuery using Cloud Run

ETL/ELT frameworks can make working on big data pipelines a lot easier, as compared to writing extraction and transformation scripts from scratch.
On the other hand, for very lightweight and standalone data extraction tasks, it's hard to beat a quick script run serverless on your cloud provider of choice.
Recently, as part of our work at Backbone, we were tasked with integrating third party Stashstock data into the Backbone internal and customer facing data warehouse(s). Integrating API data into your data warehouse commonly calls for ETL tools/platforms like Singer, Fivetran, Airbyte, or Meltano.
However in this case we wanted to avoid the complexity of these tools and opt for a simpler solution - a python script running in a Google Cloud Run app - especially because there are no existing Stashstock taps or extractors and we were only interested in extracting data from one endpoint.
Here we want to share the specifics of how we host this script, schedule it, run it incrementally (only extracting new records in each run), and store the data in BigQuery such that we have a perfect replica of the Stashstock data.
Architecture
Here's an architecture diagram showing data flowing from the partner's RESTful API to our client's data warehouse:
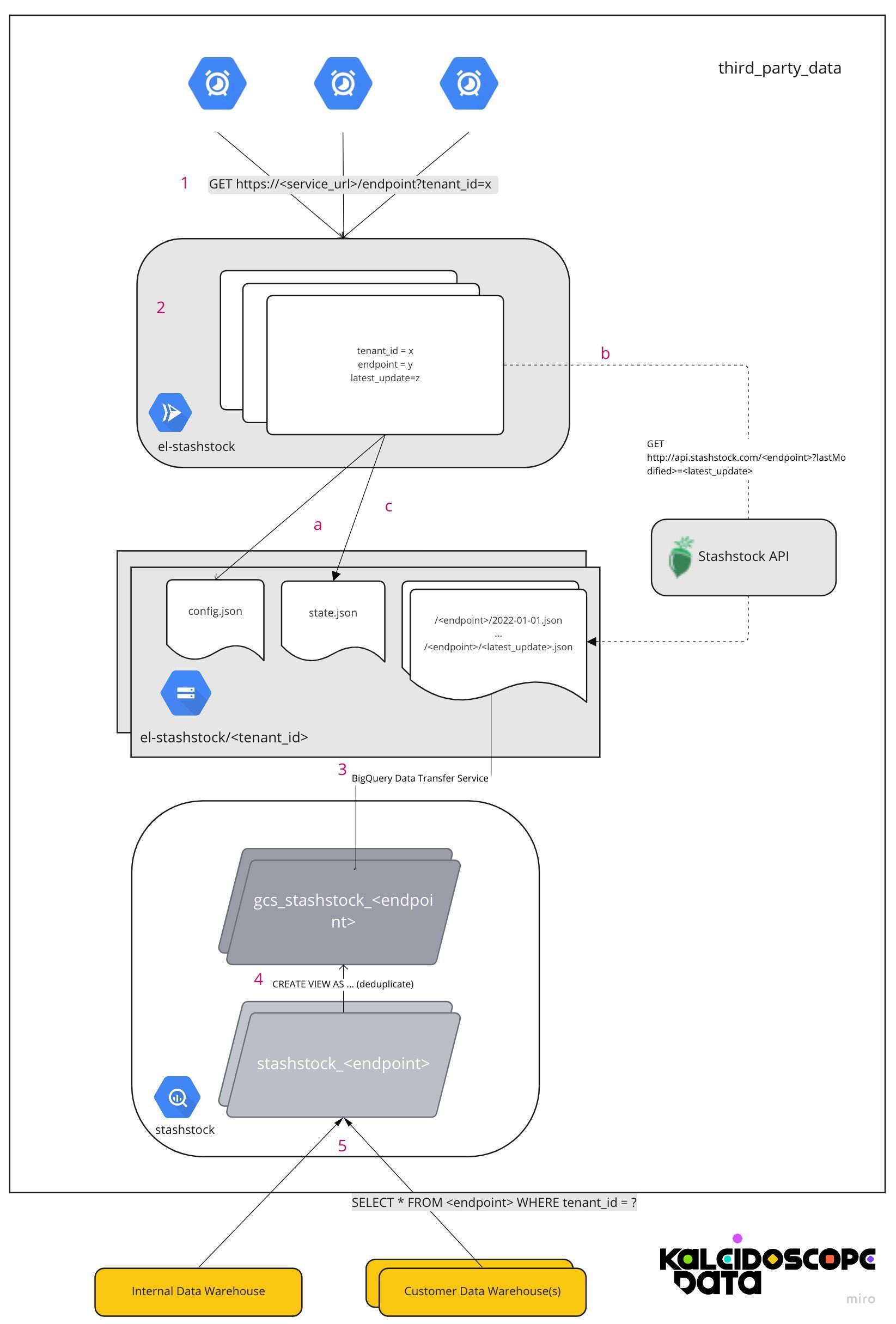
Let's walk through the steps numbered in red.
1. Scheduling/Orchestrating
Create a unique cloud scheduler task for every Extract/Load job. Here we show 3 separate tasks, but it could be any number of them. We define each job by a set of environment variables used to authenticate an API session and form the appropriate Stashstock API request URL.
To start the job, the scheduler task sends a GET request every 24 hours to the URL of our Cloud Run app named el-stashstock.
2. ELT Cloud Run App
This python/flask app accepts the GET request, parses the URL variables and query parameters and routes it into an api request to Stashstock using the following function. Here's the code:
@app.route("/<endpoint>", methods=['GET'])
def fetch(endpoint):
args = request.args.to_dict()
CONFIG_FILENAME = os.environ.get('CONFIG_FILENAME','Config filename var not set')
config = storage_utils.fetch_json(CONFIG_FILENAME)
tenant_id = args.get("tenant_id") # for example
tenant = config["tenants"][tenant_id]
STATE_FILENAME = os.environ.get('STATE_FILENAME', 'State filename var not set')
try:
state = storage_utils.fetch_json(STATE_FILENAME)
except BlobNotFoundException as e:
state = {tenant['tenant_id']:{'latest_update':'2022-01-01'}}
print(f"Syncing tenant {tenant_id}")
client = get_authenticated_client(tenant['state_code'],tenant['api_key'])
latest_update = state[tenant_id]['latest_update']
tenant_filename = f"metrc_plants_tenant-{tenant_id}_{latest_update}.json"
tenant_data,max_modified = fetch_recent_plants(client,latest_update,tenant_id)
print(f"Found {len(tenant_data)} records")
tenant_data_str = '\n'.join([json.dumps(record) for record in tenant_data])
print(storage_utils.dump_str(tenant_data_str,tenant_filename))
state[tenant_id]['latest_update'] = datetime.strftime(max_modified,DATE_FORMAT)
#successfully synced files
storage_utils.dump_json(state,STATE_FILENAME)
return f"Successfully Synced {state}"
See how we get the endpoint from the variable in the URL, the tenant_id from the request argument parameters, and the CONFIG_FILENAME and STATE_FILENAME as environment variables which are setup when we create the Cloud Run app.1
Note that these variables are not hardcoded, and that these files are not included in the app itself. We do this because Cloud Run is stateless - it does not guarantee that the next invocation of the app will contain the same set of files that the last one did. Furthermore, keeping the configuration and state outside of the app means that we can use the same app with any number of config or state files, say for different endpoints or customers/tenants.
a. Instead, we keep the config and state files in a cloud storage bucket - one for each tenant. The storage_utils.fetch_json function you see in the code fetches these files and stores them as python objects that can be updated. Here is the structure of the config file:
{
"tenants": {
"414": {
"state_code": "ca",
"api_key": "<some api key>"
},
"372": {
"state_code": "ca",
"api_key": "<some api key>"
},
...
}
}
and the state file:
{
"latest_updates": {
"414": {"metrc_plants":"2022-01-01",
"<another_endpoint>":"<another_time>"},
"372": {"metrc_plants":"2022-02-01", ...}
}
}
b. Using the config we create an authenticated Stashstock requests session client. We then pass this client to the appropriate fetch function - in this case fetch_recent_plants along with our from_date_str (created with the latest_update found in the state file), and the tenant_id found in the original query parameter.
def fetch_recent_plants(client,from_date_str,tenant_id):
url = "https://portal.stashstock.com/api/metrcext/plants/all"
out_data = []
params = {'lastModifiedStart':from_date_str}
r = client.get(url,params=params)
print(r.url)
r.raise_for_status()
max_modified = datetime.strptime(from_date_str,DATE_FORMAT)
for item in r.json():
for record in item['plants']:
record_date = dateutil.parser.isoparse(record['lastModified'])
max_modified = max(max_modified,record_date)
record['tenant_id'] = tenant_id
out_data.append(record)
return out_data,max_modified
We find it useful to have a separate function for each endpoint. Each function contains a hardcoded endpoint URL with query parameters as well as unique logic to incrementally sync the data and transform it into an array of records. It's a good idea to minimize the amount of work done by these functions and plan for many to run concurrently as Cloud Run intends. This is why we use many scheduler tasks - one for each tenant and endpoint configuration rather a single one which triggers a global sync function that loops through all of them. Note that we keep track of the max_modified date of the incoming records which we will also return to the sync function. We use these in Step C to form a new latest_update.
Once our original sync function receives these records, it dumps them in ndjson format into the same BigQuery bucket (a file format making it easy to append a stream of records to files). Each invocation creates a new document entitled /<endpoint>/<latest_update>.json so that you know not only the type of records inside but the lastModifiedStart query parameter used to fetch the records. Since all cloud storage objects contain a created and edited date you also know when the fetch was run.
If this app gets invoked twice using the same state file or runs twice in one day, it will overwrite the previous file with a superset of the old records. You could instead choose to name the files with a more exact DateTime in which case you may end up with multiple files containing many of the same records. De-duplication of these records during your Transform step of the ELT pipeline is necessary regardless of this choice, though, so its a minor trade-off.
c. When we have successfully fetched the records and dumped them to the appropriate bucket object, the sync is now complete and we can update our state object with a new latest_update - the date of the most recently fetched record. It's safer to use this rather than today's date in case there is a problem with the api or our query parameters which can result in skipped records. Finally we dump the state file back into the bucket. Those familiar with Singer may notice that this order of operations is the same as a Singer tap and target.
3. Data Transfer From Cloud Storage to BigQuery
At this point you may be wondering why we dump the API records into Cloud Storage objects rather than directly into BigQuery.
First of all, its sometimes nice to have the records in your own cloud so that you can use them outside of BigQuery. Also, if you needed to rebuild your data warehouse for some reason, it's much easier and quicker to do so from your own cloud. Furthermore, any missing records can be easier to debug. Most importantly, there is no good way to insert streaming records into BigQuery - it expects a flat file 2. Thus a very common and well supported ingest method is to load everything into object storage first. This is so common and encouraged, that the BigQuery Data Transfer Service is free for cloud storage objects and provides an easy to use, reliable way to automatically ingest ndjson files into a target BigQuery table. In our case, we run this every 24 hours just like the original cloud scheduler tasks.
4. Deduplication
We titled the table we use for our records as stashstock.gcs_metrc_plants. The gcs prefix reminds us that the table is a landing place for all Google Cloud Storage records and not necessarily a good replica of our Stashstock data, ready for analysis.
There are a few reasons why duplicates will show up at this point in the pipeline. Running the BigQuery Data Transfer service twice in a row is one of them, something we did many times during debugging. Query parameter overlaps are another one, for instance if there is confusion over which timezone is being used or returned in a chunk of data. Finally, since BigQuery uses columnular storage and does not have primary keys, there is no native "update","upsert" or equivalent to use when loading data. For all of these reasons, it's best practice to just assume that your table will have duplicates. Thus, on top of this table, we created a VIEW like so:
CREATE OR REPLACE VIEW `backbone-third-party-data.stashstock.metrc_plants` AS
select * except(row_num) from (
SELECT
*,
ROW_NUMBER() OVER ( PARTITION BY id ORDER BY lastModified
) row_num
FROM
`backbone-third-party-data.stashstock.gcs_metrc_plants`)
WHERE row_num=1
This query partitions the gcs_metrc_plants rows by their id and then orders by the last modified column so that it can select only the most recent instance of each row.
5. Analysis and Transfer to other Data Warehouses
Now finally, our stashstock.metrc_plants VIEW should be a perfect replica of the Stashstock dataset. With Backbone we use both for the internal data warehouse as well as for customer data warehouses – each customer warehouse copies only the rows pertaining to their set of tenants.

Wrapping Up
Hopefully this provides a simpler (yet cost effective) alternative to typical full-featured ETL tools, assuming you're only integrating one or two third-party data sources into your data warehouse.
For us, not only was the script much easier to write and edit if need be than a full "tap-stashstock", but it was a lot easier to Dockerize and host on Cloud Run than a Singer tap/target bash script.
Footnotes
1 We also considered using cloud functions instead of cloud run which may make hosting the python script more straightforward. However since we already had experience with Cloud Run and since it's used in a wider variety of applications it made sense to stick with it.
2 This may provide a streaming alternative. However it seems less commonly used