Data Transformation architecture for your customer-facing Data Warehouse

Most data folks understand a "Data Warehouse" as an internal tool for reporting and analytics across different teams in your organization. However, it can also be used externally - by customers who want more granular access to their data (often your largest customers).
Charging customers for this data access can provide additional revenue with relatively little overhead, and, especially in periods of uncertainty in tech and financial markets like 2022 so far, it’s worth considering how to prioritize this as a first-class product offering.
In order to offer your data warehouse as a paid customer feature, especially as your customer base grows, you may need to rethink your data warehouse architecture.
The simple and naive approach: splitting raw data first
As you add data access for the first few customers, it makes sense to create a separate warehouse for each customer in addition to your internal data warehouse. This is what it often looks like:
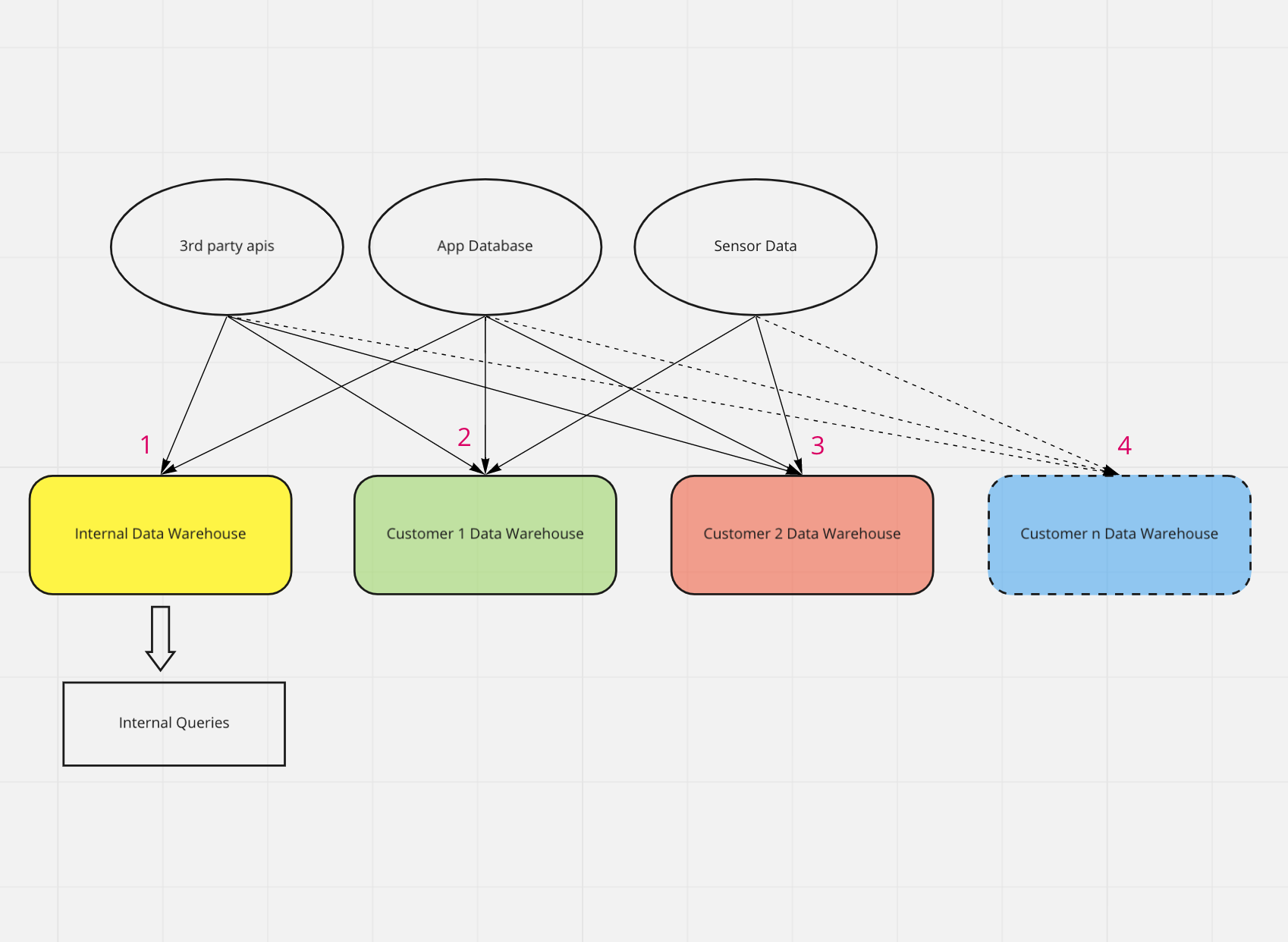
Looking at the labeled points on the diagram:
- An internal data warehouse is formed for analytics on all data. App data, third party API data, sensor data, click data, etc are all pulled in to create the reports used by data analysts working at the company.
- A customer is interested in more granular access to their data - a direct connection. Thus a customer data warehouse is created which pulls data in from the app database as well as any other data sources. All transformations are made at query time - none are stored in the warehouse. This provides very high flexibility, good security, and ease of customizations for each customer's needs
- This process continues with the next customer interested in data warehouse access...
- As more customers sign up, the number of connections you have to maintain grows. Problems arise such as customer numbers not matching in-app reports, and every change you make has to be replicated across each connection or warehouse, making you really understand the old adage DRY ("Don't Repeat Yourself").
As you can imagine, this flexibility begins to take its toll when used everywhere. Addressing the issues requires a different architecture to reduce overhead and errors.
The streamlined approach: transform first, then split
Now, instead of setting up independent connections for every new customer data warehouse, consider this: run all data through your internal data warehouse and then create copies or clones of this internal data warehouse for each customer.
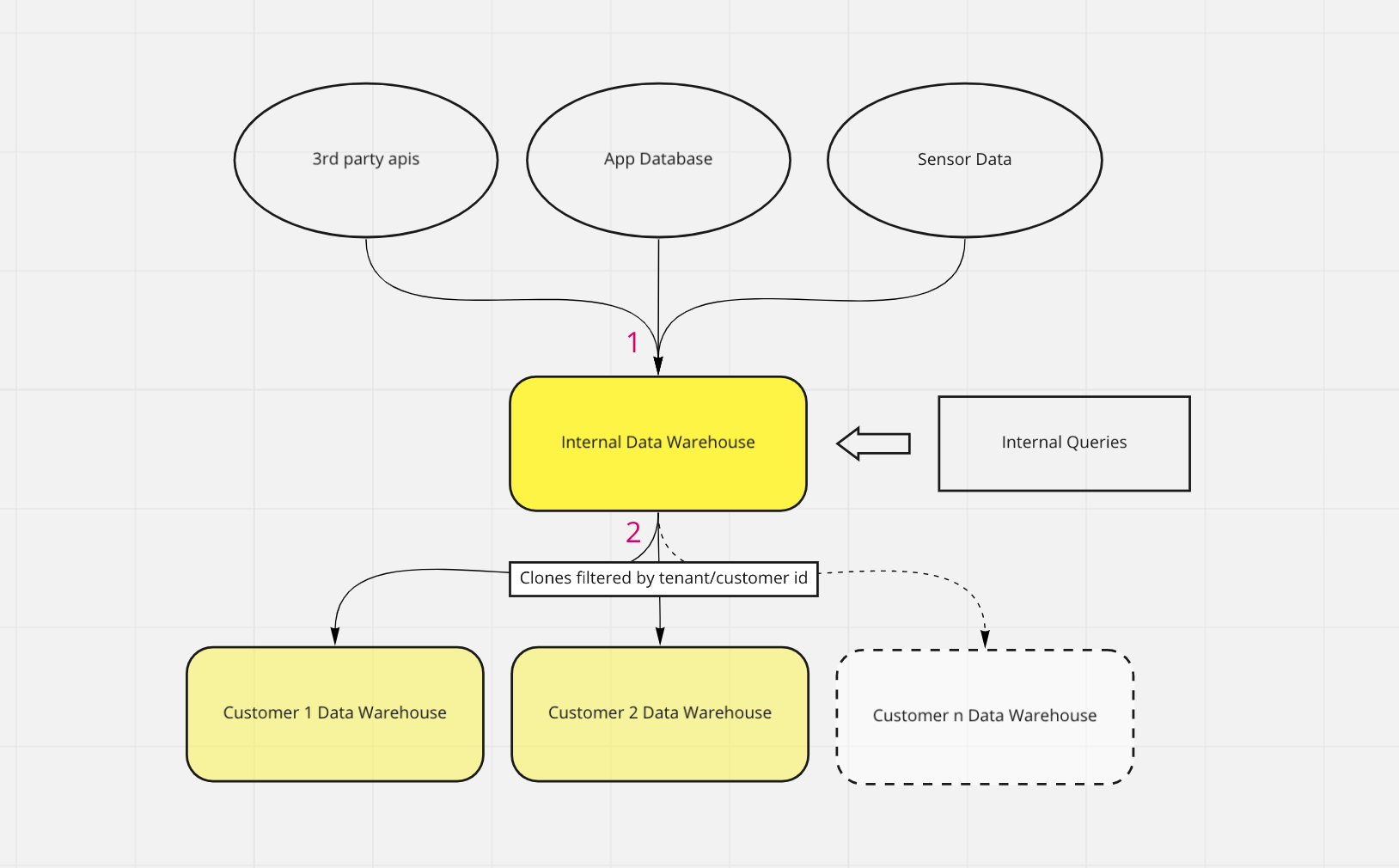
- All data sources are ingested and transformed with your internal data warehouse. This data is combined and transformed into a star schema, one big table, or convenient reporting tables to serve as the internal data warehouse used by analysts.
- Clones of this analytics/reporting schema are created for every paying data warehouse customer and pushed into customer-specific data warehouses. They share the same schema that your internal data warehouse uses. The splitting step will split out customer data warehouses using a key to identify the customer, for example a "Customer ID" or "Tenant ID" field. You'll maintain a policy of storing that Customer ID or Tenant ID field on every relevant table of your internal data warehouse.
Advantages of the "transform, then split" method
Since you're ingesting all data sources to the same location, you never have to keep track of more than a single pipeline. If numbers don’t match in your warehouse and your app, you only need to look at one place to figure out why.
Additionally, because every customer data warehouse has the exact same schema, each customer warehouse should only differ by having a different set of rows in each table. Thus you'll only need to make changes once, with all customers downstream of them.
Finally, because you're using the same schema for internal reporting that you're also giving to customers, you'll learn what works and what doesn’t (aka dog-fooding) which ultimately will improve your new product offering.
The splitting step: filtering by tenant
Now an important question arises - how do you create these clone data warehouses?
For every record in your internal data warehouse, you must maintain a tenant_id or some equivalent identifier to keep track of which rows belong to which customer. The good news is: if you do this, you can also do customer-specific reporting in your internal warehouse. This concept of including data from all customers in a single data warehouse or database is often referred to as multi-tenancy. Now you can filter out tenant/customer data from all tables with a simple query, which you can run once for each table to create views or schedule to run hourly or daily for full data replication:
select * from <table> where tenant_id = <some tenant>;
… repeat for every table…
Here we elaborate on this process using Google Cloud Platform/BigQuery for your data warehouse environment. This can get tricky if you intend for more than one customer to see a single row, in which case you may have to duplicate rows and add another column such as customer_id to delineate the difference.
Your Data Warehouse as a product
How many customer warehouses will you need to support before a switch like this makes sense? It's a difficult to answer, but if you do start feeling the pain of complexity in managing multiple customer warehouses, it may be worth considering. It's a case where a little discipline in the setup can help you in the long run. If you're considering offering your Data Warehouse as a paid product rather than an afterthought, save yourself some time and headache by planning ahead with a multi-tenant architecture like this one.