Multi-Tenancy in BigQuery
Background
Multi-tenancy in BigQuery can be accomplished in several ways. This article by the folks at Google has many helpful tips for data isolation and security. The main idea is isolating tenant data in BigQuery datasets - all under a single client data project - rather than creating a new project for every tenant. This enables consistent, trackable query performance for each tenant and geographic distribution of the data while avoiding the complexity of an ever-growing number of different projects.
However, the article also proposes writing data into each tenant dataset before performing transformations for each tenant individually. Here we propose an alternative architecture using DBT for all transformations globally before separating the data into client datasets. This has worked well for us at Kaleidoscope Data when replicating data from an app database in Cloud SQL Postgres into BigQuery.
First: why multi-tenancy?
Why would you need to worry about multi-tenancy in the first place? If you’re a B2B software company for example, you’re already serving customers via your core application, but you may want to offer an analytics-ready lens on your app data. Your larger customers particularly will demand this type of data access, to integrate with their other systems for enterprise-level reporting and analytics. Inevitably your application database will have some confusing warts you’ll want to clean up, and you may want to perform some denormalization to make data easier to access for analysts within your customer’s organization.
Architecture
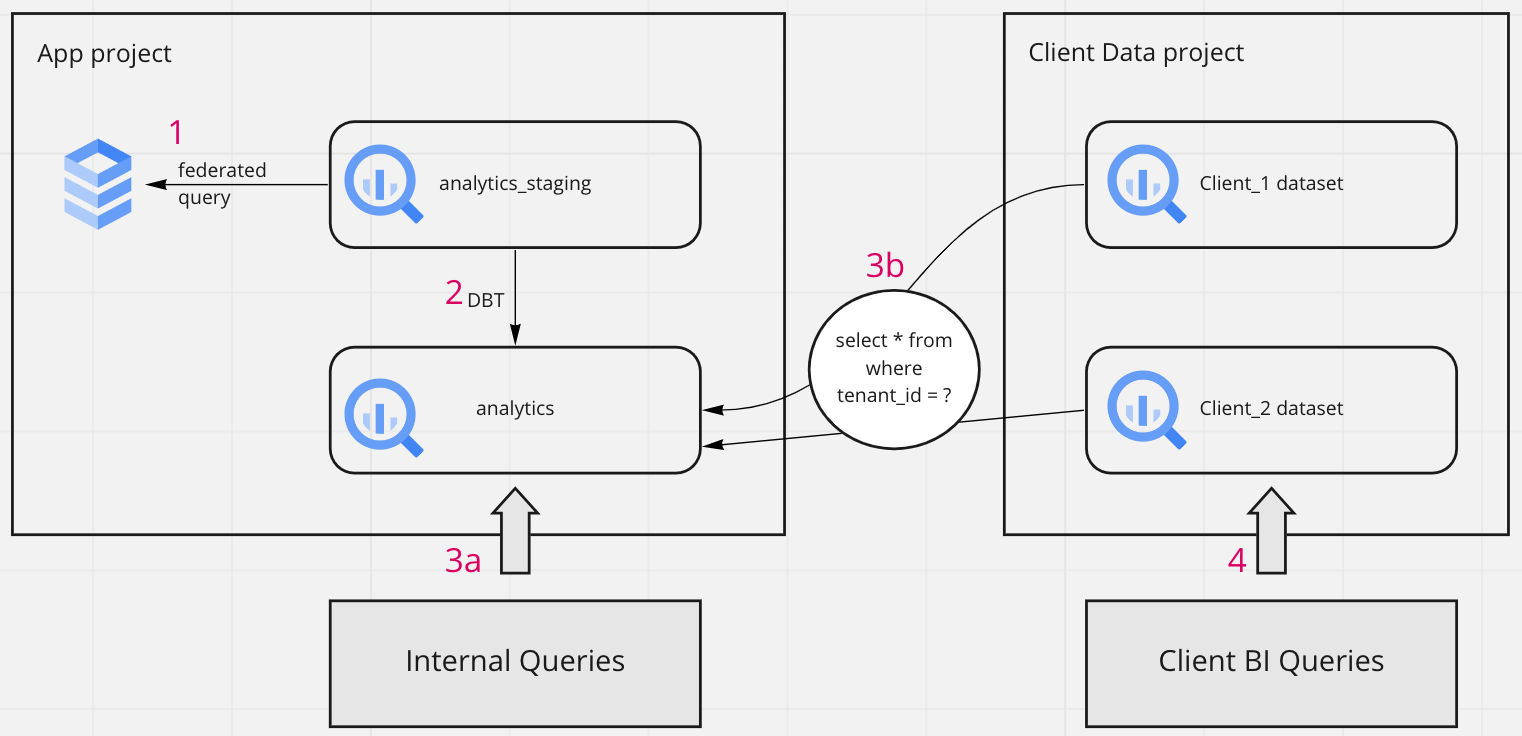
This is our proposed solution to multi-tenant data warehouses in BigQuery. The red numbers show the order of operations and the black arrows show the queries that are made and in which direction they are querying. Walking through this process step by step:
- A federated query is made against the CloudSQL instance (or a replica) to create a staging dataset.
- DBT code runs a series of transformations on all tenant data and creates the analytics schema that forms the basis of the data warehouse - this may consist of fact and dimension tables, one big table, or just convenient reporting tables that are easy to create queries for.
3a. All internal queries are made against the analytics dataset
3b. An additional single “Client Data” project contains datasets for every single one of your clients. For each of these datasets, a scheduled query is made against the internal analytics schema to filter out the data belonging to only that client - usually from a list of tenant_ids. Thus they each have a subset of the internal warehouse with the exact same schema and list of tables.
4. All clients are given a service account with access to their client dataset only. The BI tool of their choice uses this service account for all queries.
It’s important to note that this architecture mandates that every row in the analytics dataset must contain a tenant_id or some equivalent identifier column so that the rows can be filtered out in step 3b. Coincidentally, this same column can also be used to enforce row-level access on the internal warehouse if some teams deal with financial reports and others with production for instance.
Advantages
This architecture mandates all transformations take place before any reporting or querying happens. This creates two important advantages:
- Easy scaling. You can scale up to multiple clients with very little additional work. If each client warehouse is allowed or required to perform their own transformations, you will wind up supporting many disparate pipelines. It's much easier to keep track of only 1 pipeline.
- Dog-fooding your analytics schema. If you’re forced to use the same analytics schema tables as your clients to uncover insights, you’ll notice the gaps and holes that make it difficult to use. You will have a good reason to improve it and your clients will benefit when you do.
Disadvantages
- Flexibility. As shown above, this architecture mandates the use of a tenant_id or identifying feature in every row of the data warehouse. This isn’t always possible or convenient and sometimes you may have to join data from a source directly into a client warehouse. Also, time-intensive processes that are required for only a single client warehouse must be done on every warehouse as everyone is reporting on the same schema. Finally, all custom data transformation must be applied to the analytics schema rather than the base schemas from the data sources.
- Security. If you are not careful about assigning the correct tenant_id to every row, there is a chance of replicating more or less rows than you should be to each client warehouse. Both of these scenarios are bad, especially the first one. Sometimes there is a row that should be seen by multiple tenants. You must create a way to handle these scenarios*
In Summary
- BigQuery makes it easy to manage a data warehouse serving both internal staff and external users
- Multi-tenancy is a requirement for meeting needs of highest-value enterprise customers
- Perform your data transformations first, then split into tenant-specific datasets
* Sometimes an additional client_id can be used to filter the rows instead of a tenant_id which may be duplicated for two particular clients.